https://ogldev.org/www/tutorial49/tutorial49.html
Tutorial 49 - Cascaded Shadow Mapping
Background Let's take a close up look of the shadow from tutorial 47: As you can see, the qaulity of the shadow is not high. It's too blocky. We've touched on the reason for that blockiness at the end of tutorial 47 and referred to it as Perspective Aliasi
ogldev.org
기본적인 튜토리얼은 위 내용을 기반으로 구현했습니다. 다른 여러 문서들, 깃헙코드도 참고했습니다.(잘못된 부분이있으면 지적 감사합니다 )
이내용을 한글로 설명하고 DirectX11,Opengl4 를 사용하여 구현하도록 하겠습니다.
구현하면서 알게된 내용을 정리하고자 하는 글입니다.
1.Cascade Shadow Mapping?
그래픽스 공부를하면서 장면 전체에 적용되는 광원으로 디렉셔널 라이트(방향성 광원) 을 배웠습니다.
기존에 배운 기초적인 SM(Shadow Mapping) 방식으로 그림자를 만들려면 방향성 광원임에도 불구하고 빛의 위치를 정하고 해당 위치에서 빛의 방향으로 시야행렬과 투영행렬을 만들어 그림자 맵핑을 진행했습니다.
하지만 이러한 방법은 장면이 엄청 커지게되면 해당 장면을 모두 담기에는 그림자맵의 해상도가 부족합니다. 또한 어느 방향을 봐도 똑같은 방향으로 그림자가 생기게하려면 고정된 광원의 위치를 가지면 안된다고 생각했습니다.
그렇게하여 검색하던중 현재 보이는 장면에대한 그림자맵을 만드는 PSM(Perspective Shadow Mapping) 그리고 더나아가 LIPSM등 제한적인 그림자맵 해상도를 가지고 그림자 품질을 늘리는 기법에대해 검색하다 CSM(Cascade Shadow Mappoing) 을 알게되었습니다.
간단하게 설명하자면 현재 시야에 보이는 장면에 그림자를 만들기위해 단계를 나누어서 그림자맵을 만드는것이라고 할수 있습니다. 그림자맵을 나누는 기준은 시야절두체가 되며 나눠진 시야절두체 안에 들어오는 오브젝트에 대해서만 그림자맵을 만듭니다.
이런식으로 나누어서 그림자맵을 만들게되면 가까운거리에있는 물체에대한 그림자맵은 높은 정확도를 보여주게됩니다.
2.시야절두체 나누기

이렇게 시야절두체를 3부분으로 나누고 그렇게 나눠진 부분에대해 화살표(빛의 방향) 을 기준으로 투영행렬과 시야행렬을 만들어 렌더링하여 그림자맵을 만드는것입니다. 사각형영역이 투영행렬의 영역으로 해당 영역에들어온 오브젝트만 그려지게 됩니다.
후에 그림자맵에서 값을 가져와 그림자계산을 진행할때 위 사진처럼 사각형영역이 겹치는 부분이 있을것인데 그부분은 클립공간의 Z값을 비교하여 어떤 그림자맵을 사용할지 정하여 그림자맵 샘플링을 진행할것입니다.
절두체를 저렇게 3부분으로 나누려면 일단 절두체를 구성하는 점의 갯수는 8개입니다. 그렇다면 첫번째 Near 절두체를 만들기위해서는 어떻게 해야할까요? 간단한 삼각법을 이용해서 구해봅시다.

X,Z 축이 이루는 2차원 평면에서 수평각도를 알고 near와 far 값을 알면 그사이에있는 X값을 구할수 있습니다.
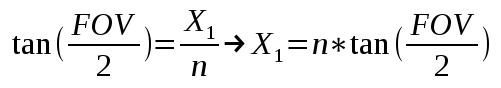
Fov 값은 수평각도의 값이며 tan(Fov/2) = x1/near 이므로 여기서 X1 = near * tan(Fov/2) 로 구할수있습니다. 이렇게 비슷한 방법으로 Far 값을 이용하여 X2의 위치를 구할수있고 이렇게 함으로써 X 좌표값은 구할 수있습니다. Y좌표도 똑같습니다 다만 다른점은 수직각도를 넣어서 구하면 8개의 좌표가 만들어지게됩니다.
물론 이방법을 사용하지않고 NDC 공간에서의 값을 투영역행렬,시야역행렬을 곱하여 시야절두체를 월드상으로 옮길수있습니다. 그리하여 near과 far 점 사이의 방향벡터를 구하여 방향벡터에 나누고자하는 near과 far 사이의 값만큼 더하여 나눌수도 있지만 저는 DirectX,Opengl 둘다 만족해야하므로 api에 따라 달라지는 NDC 공간을 기준으로 구하지 않을것입니다.
이제 위 공식들을 이용하여 3개로 나눈 절두체의 부분(Frusta)를 나타내는 16개의 점을 정의해봅시다. 아래 코드를 적겠습니다.
// 카메라의 역행렬과 시야각,화면비, 가까운 평면 Z,먼 평면 Z
glm::mat4 camInv = glm::inverse(camview);
float fov = forArNearFar->x;
float ar = forArNearFar->y;
float nearZ = forArNearFar->z;
float farZ = forArNearFar->w;
//시야각을 이용하여 수직 시야각을 구함
float tanHalfVFov = tanf(glm::radians(fov / 2.0f));
// 수직 시야각을 이용하여 수평 시야각을 구함
float tanHalfHFov = tanHalfVFov * ar;
// 절두체를 나누기위한 각 부분 절두체의 끝 지점 선언
m_cascadeEnd[0] = nearZ;
m_cascadeEnd[1] = 6.f;
m_cascadeEnd[2] = 18.f;
m_cascadeEnd[3] = farZ;
// 3개의 절두체로 나누기위해 3번 반복함
for (uint32_t i = 0; i < 3; ++i)
{
//+X,+Y 좌표에 수평,수직 시야각을 이용하여 구함. 각 부분 절두체의 가까운,먼
//평면의 값을 곱하여 4개의 점을 구함
float xn = m_cascadeEnd[i] * tanHalfHFov;
float xf = m_cascadeEnd[i + 1] * tanHalfHFov;
float yn = m_cascadeEnd[i] * tanHalfVFov;
float yf = m_cascadeEnd[i + 1] * tanHalfVFov;
//+좌표값을 구하면 -좌표값을 구하여 각각의 절두체 평면을 구할수있음.
//각 절두체의 Z값을 저장하여 i 가 낮은 순서로 가까운 평면 먼평면을 구성함
glm::vec4 frustumCorners[8] =
{
//near Face
{xn,yn,m_cascadeEnd[i],1.0f},
{-xn,yn,m_cascadeEnd[i],1.0f},
{xn,-yn,m_cascadeEnd[i],1.0f},
{-xn,-yn,m_cascadeEnd[i],1.0f},
//far Face
{xf,yf,m_cascadeEnd[i + 1],1.0f},
{-xf,yf,m_cascadeEnd[i + 1],1.0f},
{xf,-yf,m_cascadeEnd[i + 1],1.0f},
{-xf,-yf,m_cascadeEnd[i + 1],1.0f}
};코드에서 설명한대로 절두체를 나누기위해서 각 절두체의 경계면을 정의하는 Z값을 정의합니다. 이부분은 임의로 지정해도 되지만 아래 마이크로 소프트 캐스케이드 쉐도우맵 문서에서는 각 간격(Interval)을 정하는방법이 나와있습니다.
이것은 그림자맵을 나눌때 장면기준이나 절두체기준이냐 에 따라 다르다 자세한내용은 아래 문서를 확인해봅시다.(저도 자세히는 모릅니다 ㅠㅠ)
https://docs.microsoft.com/en-us/windows/win32/dxtecharts/cascaded-shadow-maps
절두체를 이루는 점을 구했으면 빛의 시점에서 렌더링하기위해 각 절두체에 맞는 투영행렬을 만들어야합니다. 위에있는 절두체를 나눈 사진에서 빛의 시점 그리고 빛의 공간상에서 절두체에 존재하는 물체를 그리기위한 범위를 정해야합니다. 범위를 정할때 디렉셔널 라이트에서 사용하는 직교투영행렬을 이용하게되는데 직교투영행렬을 만들때 좌우상하의 범위는 해당 절두체 범위를 전부다 덮는 범위여야하며 깊이 범위도 똑같습니다.
위에서 만든 절두체의 꼭지점은 시야공간에 있는 점입니다. 시야공간에서 월드공간으로 이동시켜줘야하므로 각 꼭지점에 시야역행렬을 곱해줍니다. 그이후작업은 이제 직교투영행렬을 만들기위한 범위를 정해야하는데. 직교투영행렬의 Z범위는 당연히 현재 절두체의 가까운평면과 먼평면으로 지정됩니다. 다만 좌우상하의 범위는 절두체 안의 모든오브젝트를 담으려면 절두체꼭지점의 범위가 될것입니다.
각 꼭지점의 최대,최소 X,Y 값을 구하면됩니다. 구한값을 가지고 직교투영행렬을 만들면되지만 이렇게 만든 직교투영행렬을 이용하여 그림자맵핑을 진행하고 해당 그림자맵을 디버깅용도로 렌더링했을때 카메라의 시점에따라 변형되는 모습을 볼 수 있습니다. 이대로 사용해도 무리는 없지만 변형되지않은 그림자맵을 렌더링하고 싶으면 각꼭지점에서 직교투영이 이루는 직사각형의 중앙 즉 절두체의 중점과 꼭지점의 거리중 가장 긴 길이를 가지고 좌우상하가 똑같은 직교투영행렬을 만들면됩니다.
glm::vec4 centerPos = glm::vec4(0.0f);
for (uint32_t j = 0; j < 8; ++j)
{
frustumCorners[j] = camInv * frustumCorners[j];
centerPos += frustumCorners[j];
}
centerPos /= 8.0f;
float radius = 0.0f;
for (uint32_t j = 0; j < 8; ++j)
{
float distance = glm::length(frustumCorners[j] - centerPos);
radius = std::max(radius, distance);
}
radius = std::ceil(radius * 16.0f) / 16.0f;
// using radius , we made aabb box
glm::vec3 maxExtents = glm::vec3(radius, radius, radius);
glm::vec3 minExtents = -maxExtents;
glm::vec3 shadowCamPos = glm::vec3(centerPos) + (glm::normalize(lightDirection) * (minExtents.z));
glm::mat4 lightMatrix = glm::lookAt(shadowCamPos, glm::vec3(centerPos), glm::vec3(0.0f, 1.0f, 0.0f));
glm::vec3 cascadeExtents = maxExtents - minExtents;
if (RenderAPI::GetAPI() == RenderAPI::API::DirectX11)
m_shadowOrthoProj[i] = glm::orthoLH_ZO(minExtents.x, maxExtents.x, minExtents.y, maxExtents.y, 0.0f, cascadeExtents.z) * lightMatrix;
else
m_shadowOrthoProj[i] = glm::orthoLH_NO(minExtents.x, maxExtents.x, minExtents.y, maxExtents.y,0.0f, cascadeExtents.z) * lightMatrix;
}코드를 하나대로 정리하자면 절두체의 중점위치를 저장할 변수가 있습니다. 각 꼭지점을 반복하면서 시야공간에서 월드공간으로 변환후 해당 월드공간의 꼭지점을 모두 더합니다. 더한 값을 절두체 꼭지점 갯수인 8로 나누게되면 절두체 중점위치가 나오게됩니다.
이제 중점과 꼭지점 사이의 길이가 가장큰 길이를 구하고 해당 길이를 반지름으로 사용합니다. 반지름을 기준으로 정육면체를 이루는 AABB 바운딩 박스를 구성할것입니다. 그렇다면 가장큰 값은 x,y,z 축이 반지름 값인경우이고 그반대는 -값으로 이루어져있을것입니다.
그다음 코드는 만약 문서 초반에있는 튜토리얼 링크에서는 모든 절두체 정점을 다시 빛의공간으로 이동시켜 빛이 원점을 기준으로 하므로 카메라의 위치가 따로 필요하지않습니다. 하지만 그방법대신 각 절두체에대한 상대적인 빛의 위치를 정할것입니다. 왜냐하면 만들어진 직교투영행렬에 맞게 빛의 기준에서 오브젝트를 렌더링할것이기 떄문입니다.
빛의 위치를 절두체 중점으로 해주고 가까운평면,먼평면을 직교투영에 각각의 maxExtents,minExtents 값으로 지정해도좋지만 빛의 위치를 중점에서 빛의 방향으로 -반지름만큼 더함으로써 뒤로 빼줍니다. 그다음 해당 빛의 위치에서 절두체 중점을 바라보는 시야행렬을 만들고 직교투영행렬을 만들때는 가까운Z값은 0.0f로 해줍니다(왜냐하면 -반지름만큼 뒤로 뺏기때문에 0.0f에서 바라봅니다)
cascadeExtents값은 그냥 지름값이라고 생각하면됩니다. 그후 glm 라이브러리를 사용하는데 이부분에서 OpenGL을 사용하냐 아니면 DirectX를 사용하냐에 따라 다릅니다. 두 API의 NDC 공간상의 Z값의 범위가 다르므로 GL의 경우에는 NO 즉 -1~1 사이의 값인 투영행렬을 사용하고 DX의 경우 ZO 0~1 로 변환하는 투영행렬을 사용하시길 바랍니다. 서로 잘못쓸경우 Z값의 범위가 반토막나버려 원하는 결과가 나오지 않게됩니다.
이 한번의 과정이 절두체 하나의 시야투영행렬을 구하는 과정입니다. 원하는 분할단계에따라 각 절두체의 시야투영행렬을 구했으면 이제 해당 행렬을 가지고 그림자맵을 만들 차례입니다.
이제 쉐이더단계에서 그림자맵을 그릴것인데 저는 3단계로 나누기로 했으므로 길이가 3인 Texture2DArray를 사용하도록하겠습니다. 배열사용을 원하지않는 분들은 따로 나누어 3개의 Texture2D를 사용하셔도 무방합니다. 다만 각 절두체 단계마다 전체씬 렌더링을 수행해야하므로 3번의 드로우콜을 방지하기위해 저는 기하셰이더를 사용하기위해 텍스쳐배열을 사용합니다.
제가 따로 생각한 최적화방법은 3개의 절두체가있으므로 각 절두체마다 절두체컬링으로 각 단계별로 렌더링할 오브젝트를 모아서 드로우콜을 최소한으로 줄이는것이있긴한데 정확히 더나은 성능을 보장할지는 모르겠습니다. 단순히 기하세이더로 간단히 구현해보겠습니다.
gl,dx 환경에따라 gl의경우 프레임버퍼,dx의 경우 깊이스텐실뷰 를 준비하시고 해당 버퍼 혹은 뷰에 텍스쳐배열을 사용하도록합니다. 그후 해당 프레임버퍼가 깊이텍스쳐로 사용하도록 하면 됩니다.
//Cascade Shadow Map applied
#type vertex
struct VSIn
{
float3 pos : a_Position;
float3 normal : a_Normal;
float2 tc : a_TexCoord;
};
cbuffer Transform : register(b0)
{
matrix u_Transform;
matrix u_InvTransform;
}
struct VSOut
{
float2 tc : Texcoords;
float4 position : SV_POSITION;
};
VSOut VSMain(VSIn input)
{
VSOut output;
output.tc = input.tc;
output.position = mul(u_Transform, float4(input.pos, 1.0f));
return output;
}
#type geometry
cbuffer LightTransform : register(b1)
{
matrix lightTransform[3];
}
struct GSIn
{
float2 tc : Texcoords;
float4 position : SV_POSITION;
};
struct GSOutput
{
float2 tc : Texcoords;
float4 pos : SV_POSITION;
uint RTIndex : SV_RenderTargetArrayIndex;
};
[maxvertexcount(9)]
void GSMain(triangle GSIn input[3], inout TriangleStream <GSOutput> output)
{
for (int face = 0; face < 3; ++face)
{
GSOutput element;
element.RTIndex = face;
for (int i = 0; i < 3; ++i)
{
element.pos = mul(lightTransform[face], input[i].position);
element.tc = input[i].tc;
output.Append(element);
}
output.RestartStrip();
}
}
#type pixel
struct PSIn
{
float2 tc : Texcoords;
float4 position : SV_POSITION;
};
void PSMain(PSIn input)
{
}위 코드는 정점,기하,픽셀쉐이더를 한꺼번에 담은 hlsl 파일입니다. glsl 파일대신 설명하겠습니다. 각각상응되는 개념은 인터넷에서 금방 찾으실수 있으니 원리만 금방 설명하도록하겠습니다.
첫번째로 정점쉐이더에서는 모델행렬을 가지고 정점을 월드공간으로 변환합니다. 변환된 정점을 기하세이더로 전달해주는데 여기서 maxvertexcount (9) 는 반환되는 최종 정점의 갯수가 9개라는 뜻입니다. 삼각형으로 치면 3개의 삼각형을 반환하겠죠? gl 에서의 상응하는 키워드는 layout(triangle_strip,max_vertices=9) out; 입니다 9개의 정점이나가고 삼각형 스트립으로 반환된다는 뜻입니다.
그후 GSMain 으로 받는 정점쉐이더에서 전달해주는 GSIn 구조체정보를가진 3개의 정점을 받고 그것을 반환할 inout키워드로 지정되고 TriangleStream 으로 반환되는 구조체정보 GSOutput을 가지는 정점으로 반환합니다.
기하셰이더안에서 첫번째 반복문이 있는데 이것은 텍스쳐배열의 인덱싱을 위한 반복문입니다. RTIndex 이 키워드가 GSOutput 구조체에서 정의된 시스템밸류 시멘틱입니다. 해당값을 이용하여 배열의 어느부분에 접근할지 정합니다. 그후 두번째 반복문ㅇ ㅔ집입하는데 이 반복문에서는 해당배열에 빛의시야투영행렬을 곱하여그립니다. 중요한점은 Cbuffer에 이전에 만든 각 절두체의 빛의시야투영행렬 3개가 들어있다는것입니다. 순서대로 넣었다고 가정하고 배열의 인덱스에 맞게 가까운 절두체의 시야투영행렬을 가져와 곱해줍니다. 이렇게 3개의 점점에 곱하고 RestartStrip() 함수를 호출하게되면 3개의 만들어진 정점들을 이어줍니다 그리고 다음 반복문으로 돌아갑니다.
마지막 픽셀쉐이더에서는 따로 작업할것이없기때문에 공백으로 남겨둡니다. 이렇게되면 OM (outputmerger) 단계 에서 깊이값만 쓰일것입니다.
이런식으로 총 9개 즉 3개의 삼각형이 각각의 텍스쳐배열에 쓰여지게됩니다. 배열의 인덱스가 증가할수록 가까운 절두체에서 먼절두체로 이동하면서 3개의 삼각형을 그리게됩니다. 이런식으로 기하세이더를 사용하면 한번의 드로우콜만으로 3개의 그림자맵을 구할수있습니다.
이제 그림자맵을 이용하여 그림자를 그리는 작업으로 넘어갈 차례입니다.
넘어가기전 그림자를 그리는 셰이더에 넘겨줄 데이터가 한가지있습니다. 위에서 만든 3개의 시야투영행렬뿐만아니라 절두체를 분할하기전 기준이됬던 Z값을 기준으로 클립공간의 Z값이 필요합니다 오브젝트를 렌더링할때 만들어진 그림자맵중 거리에따라 어떤 그림자맵을 사용할지 정할 기준이 되기때문입니다.
여기서 투영행렬은 현재 보여지는 카메라와 후에 오브젝트를 렌더링할때 사용하는 카메라의 투영행렬과 같다는 가정입니다! 그래야 카메라기준의 Z값이 투영행렬로 변환후 클립스페이스에있는 오브젝트와 같은공간에 있기때문입니다!
for (int i = 0; i < 3; ++i)
{
glm::vec4 vclip = (*projectionMatrix) * glm::vec4(0.0f, 0.0f, m_cascadeEnd[i + 1], 1.0f);
DirlightTransform->cascadedEndClip[i].x = vclip.z;
}이제 쉐이더 코드를 살펴보도록하겠습니다.
cbuffer LightTransform : register(b4)
{
matrix lightPV[3];
float cascadeEndClipSpace[3];
}
//Shadow Map
Texture2DArray cascadeShadowMap : register(t8);
SamplerComparisonState cascadeShadowMapSplr : register(s8);
float CalcCascadeShadowFactor(int cascadeIndex, float4 lightspacepos)
{
float3 projCoords = lightspacepos.xyz / lightspacepos.w;
projCoords.x = projCoords.x * 0.5 + 0.5f;
projCoords.y = -projCoords.y * 0.5 + 0.5f;
if (projCoords.z > 1.0)
return 0.0f;
float currentDepth = projCoords.z;
float bias = 0.01f;
float shadow = 0.0;
float3 samplePos = projCoords;
samplePos.z = cascadeIndex;
[unroll]
for (int x = -1; x <= 1; ++x)
{
for (int y = -1; y <= 1; ++y)
{
shadow += cascadeShadowMap.SampleCmpLevelZero(cascadeShadowMapSplr, samplePos, currentDepth - bias, int2(x, y));
}
}
shadow /= 9.0f;
return shadow;
}
PS_OUT PSMain(PSIn input)
{
[unroll]
for (int i = 0; i < 3; ++i)
{
cascadeLightPos[i] = mul(lightPVW[i], float4(input.fragPos, 1.0f));
}
[unroll]
for (int j = 0; j < 3; ++j)
{
if (input.clipSpacePosZ <= cascadeEndClipSpace[j])
{
shadowFactor = CalcCascadeShadowFactor(j, cascadeLightPos[j]);
debugColor = checkcolor[j];
break;
}
}
...
..
.그림자계수를 계산하는 쉐이딩 코드만 가져왔습니다. 이코드는 픽셀세이더코드입니다. 여기서 보아야할부분은 Cbuffer로 넘기는 정보를 보시면됩니다. 이전 정점쉐이더에서 받은 PSIn 구조체에는 월드공간의 정점위치인 fragPos가 있습니다. 해당 정점을 가지고 각 절두체에 해당하는 빛의공간으로 변환하기위해 각각의 시야투영행렬을 사용하여 3개의 빛의공간상 정점을 구해줍니다.
정점이 구해졌다면 이제 input.clipSpacePosZ 값에 주의해주세요 따로 코드로 올리지않고 설명하도록하겠습니다. 이값은 정점쉐이더에서 현재 카메라의 시야투영행렬(빛의 시야투영해열이아님) 을 이용하여 얻은 SV_POSITION 의 z값입니다. (gl 에서는 gl_Position) 이값을 저장한 변수로 이값과 위에서 따로 전달하는 카메라공간의 절두체를 나누는간격값과 비교하여 어떤 그림자맵을 사용할지 정합니다. 조건문에서 작거나 같을경우 해당 인덱스의 텍스쳐를 사용합니다. 동시에 해당 인덱스값으로 빛의공간상정점도 넘겨줍니다
(자세히 생각해보니 이 코드에 최적화의 여지가 있는것같습니다. 첫번째 반복문에서 미리 3개의 빛의공간상 정점을 구하는것이아니라. 아래 반복문에서 인덱스가 결정되면 한꺼번에 고르는것입니다..)
이제 그림자계수를 구하는 함수에서는 다른 그림자맵핑 코드와 똑같습니다. 다만 이코드에서는 3x3 Hardware PCF를 진행합니다. Haredware PCF를 모르신다면 반복문 코드를 다 없애시고 Sample 함수로 대체하셔도 무방합니다!
여기서 한가지 짚고 넘어가야할 부분은 투영좌표를 텍스쳐좌표로 이동시키는 부분인데 GL,DX에 따라서 잘 변환하시길 바랍니다.! DX의 경우는 위코드처럼 Y좌표를 반대로해주고 Z값은 그대로 둡니다 하지만 GL의경우는 X,Y,Z값에 같은 공식을 적용하면됩니다!
(텍스쳐 배열의 샘플링은 MSDN에 잘나와있으니 검색해보시는게 빠를겁니다. 간단하게 설명하자면 2번째 파라메터는 float3을 받는데 float3의 x,y는 텍스쳐의 위치 남은 z값이 텍스쳐배열의 인덱스를 의미합니다. 그리고 3번째 파라메터가 만약 텍스쳐샘플링에 비교모드가 켜졌을경우 비교할값을 넣는곳, 마지막 파라메터는 오프셋을위한 변수입니다. gl의경우 texture 함수를 사용하는데 두번째 파라메터로 vec4를 받습니다)
-결과-

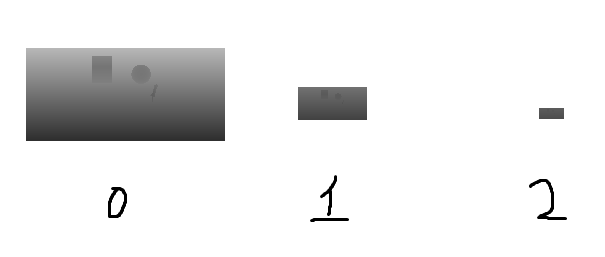
왼쪽에서 오른쪽으로 갈수록 멀리있는 절두체입니다. 현재 카메라 투영행렬의 가까운 Z 는 0.05f 먼 Z는 50.0f 기준입니다.

이런식으로 빨간부분이 가까운절두체의 영역이며 텍스쳐배열의 0번째 그림자맵을 사용하여 그림자를 계산하는부분이며 파란부분은 그다음 그림자맵을 이용하여 그림자를 계산합니다.

절두체의 경계선에서 해당 현상이일어납니다. 서로다른 그림자맵을 사용하기떄문입니다. 또한 이미지에서는 표현되지않지만 카메라가 움직일때 그림자의 경계선에서 미세한 움직임이 보입니다. 위 에서 원을 반지름으로 바운딩박스를 만든것은 카메라의 회전에의해 그림자가 떨리는것을 막는 작업이었습니다.
이번에는 카메라위치의 변화에대한 그림자가 떨리는것을 막기위해 오프셋작업을해줘야합니다.
glm::mat4 lightOrthoMatrix;
if (RenderAPI::GetAPI() == RenderAPI::API::DirectX11)
lightOrthoMatrix = glm::orthoLH_ZO(minExtents.x, maxExtents.x, minExtents.y, maxExtents.y, 0.0f, cascadeExtents.z) ;
else
lightOrthoMatrix = glm::orthoLH_NO(minExtents.x, maxExtents.x, minExtents.y, maxExtents.y,0.0f, cascadeExtents.z) ;
glm::vec4 shadowOrigin = glm::vec4(0.0f, 0.0f, 0.0f, 1.0f);
shadowOrigin = lightOrthoMatrix * lightViewMatrix * shadowOrigin;
shadowOrigin = shadowOrigin * (1024.f / 2.0f);
glm::vec4 roundedOrigin = glm::round(shadowOrigin);
glm::vec4 roundOffset = roundedOrigin - shadowOrigin;
roundOffset = roundOffset * 2.0f / 1024.f;
roundOffset.z = 0.0f;
roundOffset.w = 0.0f;
lightOrthoMatrix[3] += roundOffset;
m_shadowOrthoProj[i] = lightOrthoMatrix * lightViewMatrix;위에서 언급한 코드에서 추가적으로 들어간내용은 만들어진 투영행렬와 시야행렬을 이용하여 원점에있는 벡터에 곱하고 해당 벡터에 그림자 해상도의 반만큼 곱합니다. 이렇게 구한값을 반올림한값과의 감산을 통하여 오프셋벡터를 구합니다. 해당 오프셋벡터에 다시 그림자 해상도 나누기 2의 역수를 곱해줍니다.
이렇게 얻은 벡터를 투영행렬의 4행(위치이동) 부분에 더해줌으로써 보정을해줍니다.
(이과정이 정확하게 어떤것을 의미하는지는 잘모르겠습니다. 다만 카메라위치에따른 오차가 생기는걸까요?)
'그래픽스' 카테고리의 다른 글
| Assimp 를 이용하여 모델불러오기 (0) | 2021.08.10 |
|---|---|
| 다중광원과 그림자 구현하기 (Multiple Light and Shadow) - 스폿라이트 (0) | 2021.08.06 |
| 다중광원과 그림자 구현하기 (Multiple Light and Shadow) - 포인트라이트 (0) | 2021.08.05 |
| Cascade Shadow Map Pratical Split Scheme (0) | 2021.07.30 |
| Cascade Shadow Map Seam artifact해결 및 Fade 효과 (0) | 2021.07.29 |



